
Deep learning Glossary
Recently I have focused more on Deep learning area and would like to document my journey. So, in this post, I am going through its fundamental glossary which gives you a better understanding of its concepts.
Deep learning is among the most prominent methods in Artificial intelligence with most applicability in Text/Image/Audio processing, Time series analysis, and so on. Let’s get started:
Activation function: It is a mathematical function to apply on set of inputs such as weight & biases. This function is converting the input to output and its main goal is enabling the model to learn complex data patterns. There have various activation functions such as Relu, Leaky Relu, Tanh, Sigmoid, Softmax, etc.
Good reference: https://www.analyticsvidhya.com/blog/2020/01/fundamentals-deep-learning-activation-functions-when-to-use-them/
Backpropagation: It is a method for fine-tunning the model parameters such as weight. In a feed forwarding neural network, the prediction errors are propagating back to the neural network to improve weight and biases of the neural network based on the error rate in previous epochs. The steps are:
- Initialize weights in the neural network randomly
- Do training & make a prediction
- Calculate the error of prediction
- If the error of prediction is not minimized:
- Adjust parameters and return back them to neural network
- Return to the second step, until the prediction error is minimized
More details in the section on Gradient descent.
Good reference: http://neuralnetworksanddeeplearning.com/chap2.html
Drop out: This is a regularization method to reduce overfitting in the training phase by zeroing (shutting down) randomly some of the units with a given probability in a neural network, it is super handy when we have large networks. Drop out method can be applied to both input & hidden layers.
Pooling: This is a building block in the Convolutional Neural Network (CNN) to reduce the amount of data and parameters by downsampling using filters. There are two common ways to do pooling: Max pooling & Average pooling.
Let’s show it by an example, consider that we have a 4x4 matrix with a Max pooling 2x2 filter with stride 2. So for each region, we take the max value of the region and shift two steps each time:
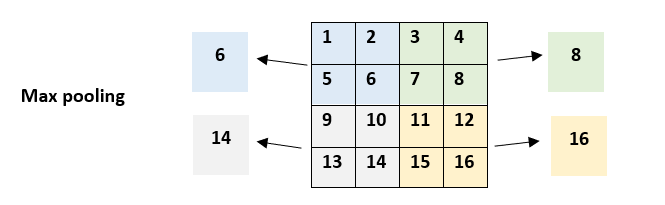
Good reference: https://machinelearningmastery.com/pooling-layers-for-convolutional-neural-networks/
Convolution: This is a process used in the Convolutional neural network(CNN) network to generate convoluted features to reduce the number of parameters. This process is done by sliding a filter(kernel) on the input data to perform element-wise multiplication and sum up all the values, let’s show this by an example:
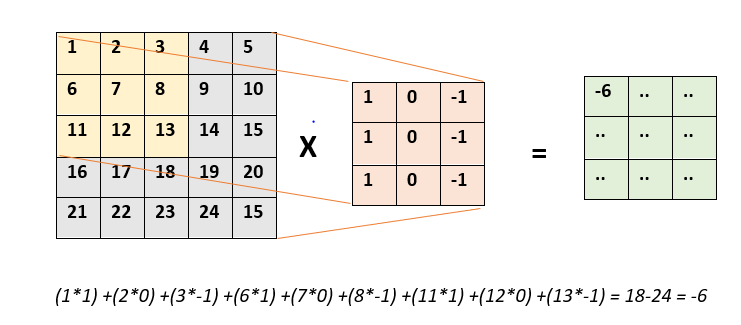
Good reference: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
Gradient Descent: This is an optimization algorithm to find the best parameters in our model to have a minimum value for loss function. Gradient Descent step downs the loss function in the direction of the steepest descent.
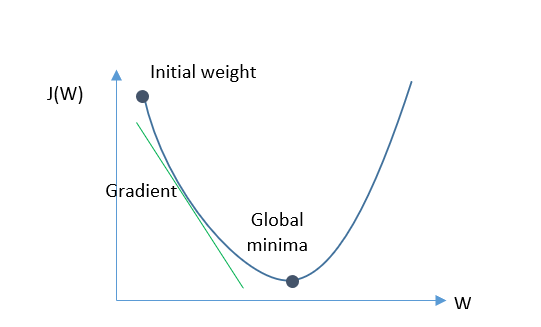
For achieving this, we need to calculate the gradient of the loss function and then update existing parameters, and this continues until we reach a minimum value for the loss function. Gradient descent may not find a global minimum and get stuck at a local minimum. In details the process is like:
- Start parameters randomly
- Do training & calculate the output
- Use loss function to calculate the error of predicted & real output
- Return Information back to the network (backpropagation), for this we need to:
- Update & adjust parameters
- For updating parameters, we need 3 elements:
- Old parameter value
- Learning rate: a value that defines how much we are changing parameter, it can be small or big
- The gradient of loss function: calculate derivative of loss function respect to parameter
- The positive gradient tells us that slope goes up
- The positive gradient tells us that slope goes down
- If the derivative is zero, it means the slope does not go up or down
- For updating parameters, we need 3 elements:
- Update & adjust parameters

- Return to the second step and iterate until we reach the minimum value
There are various gradient types such as Batch gradient descent, Stochastic gradient descent (SGD), and Mini batch gradient descent.
- In the Batch gradient descent, all training data are introduced per epoch, and the gradient is calculated using all the data. The main drawback of this methods is that we may stuck into local minimum and processing all training at data at once can be too large for memory
- In Stochastic gradient descent, only one single training data is introduced in each epoch, the gradient is calculated using that sample, and parameters are updated for each training data. The main drawback of this method is computation time and its slowness
- Mini batch gradient descent is a combination of both the above methods, training data is divided into N samples, and gradients calculation and parameter updates are happening at each epoch using N sample. The advantage of this method is faster training time and having randomness in data which leads to a higher chance of finding local minima
Good reference: https://www.youtube.com/watch?v=cxPAvoIbsIk
Learning Rate: It is a hyperparameter in Neural network that defines how much we are changing weights of the neural network with respect to loss gradient. Small values lead to slower training time and may due to the limitation of time & resources we don’t each local minimum; on the other hand, high value brings the risk that we pass over the minimum and we fail to converge.
Vanishing Gradient: When we have a deep network with many layers that uses backpropagation and gradient-based learning, the problem of exploding & vanishing gradient may rise. Gradient is a way to calculate and adjust network weights & biases and it is calculated by making derivation out of an activation function such as sigmoid, and derivation of a sigmoid is vanishingly small. Consider the situation in a deep network that when we have n layers, so we are using n sigmoid functions and n small derivation are multiplied together, which leads to a really small value and it prevents weight to change its value and the network may not learn further and doesn't converge.
Cost function: This is a way to quantify the performance of the learning model. Cost functions calculating and measuring prediction error by comparing predicted and expected values. The objective of training in Neural network is to minimize (in some cases maximize) cost function as much as possible. We have other terminology similar to cost function: loss function. Loss function is used to quantify the error in single training while cost function is the average of loss functions.
In another post, I will write about types of neural networks such as Autoencoders, CNN, RNN, LSTM, etc. Stay tuned!